If you remember nothing else:
- Claude Code plans are detailed and well-structured but execution drifts, especially in long sessions where context compresses
- Written instructions in CLAUDE.md work until they fade from context. Hooks work always, because they run as separate processes.
- The difference between exit code 1 and exit code 2 is the difference between "logged and ignored" and "actually blocked"
- Build a regression test suite before you trust any hook. I found 6 bugs in mine that testing alone uncovered.
- A hook verifies that the steps ran. Only plan mode and a real interview verify they were the right steps.
I had a 12-step plan. Claude executed 9 of them. The other 3 were silently skipped. No error. No warning. Just missing.
Claude said “done.” I checked the files. Steps 4, 7, and 11 were not there. Not partially done. Not attempted and failed. Just absent, as if Claude had never read them.
This happened three times before I decided to fix it. Three times. That is the part that bothers me looking back, because the failure looked the same every time and I still kept assuming each instance was a one-off. The fix took a weekend, produced 6 bugs, required 15 regression tests, and resulted in a system that has not missed a step since. Here is the whole story.
What’s the problem nobody talks about?
Claude Code’s plan mode is brilliant for planning. You enter plan mode, Claude explores your codebase, asks questions, and produces a detailed numbered plan with file paths, specific changes, and verification steps. What I love about this is the way it forces specificity early, so by the time you click into execution you already know which files matter.
Execution is where it falls apart.
In building Tallyfy, I have watched this pattern repeat with AI tools for years. The AI does exceptional analytical work and then fumbles the follow-through. It isn’t a Claude-specific problem. It is a fundamental issue with how large language models handle long sequential tasks.
What happens specifically: Claude starts executing a 10-step plan. Around step 6 or 7, context compression kicks in. The model’s context window is approaching its limit, so earlier messages (including the plan itself) get summarized. The detailed numbered steps become a vague summary. Claude continues executing based on its compressed memory of what the plan said, not the actual plan.
The result? Steps get skipped. Strike that. “Skipped” implies intent. The accurate word is “forgotten.” They aren’t skipped because Claude decided to skip them. They’re missed because Claude doesn’t remember they exist.
Sit with that distinction for a second, because it changes how you fix the problem. A model that decides to skip work can be argued out of it. You can tell it the work matters, raise the stakes, repeat the instruction. A model that has lost the memory of the work cannot be argued with at all. There is nothing to argue against. The plan, as far as that compressed context is concerned, never had a step 7. You can write “do every step” in capital letters and it will agree, because it agrees with the version of the plan it can still see, and that version is shorter than the one you wrote.
This is also why the failure is so quiet. Picture two ways a step could go wrong. In the first, Claude reads step 7, tries it, hits an error, and tells you. That is loud. You see the error, you fix it, you move on. In the second, Claude never reads step 7 because step 7 was summarized into a phrase, and the phrase did not survive. There is no error to surface. There is no “I could not do this.” There is just a session that ends with “done” and a file that is missing a change you asked for three messages ago. The first kind of failure trains you. The second kind ambushes you, and it ambushes you most on exactly the long, important jobs where the plan was longest and mattered most.
Why plans fail in practice
Actually, let me back up. There are five failure modes here. I hit the first four head-on while building the hook system, and the fifth sits upstream of all of them.
Context compression. Long sessions summarize earlier messages to make room for new ones. Your 12-step plan with specific file paths becomes “the plan involved updating several files.” Claude can’t execute specifics from a summary. This is the most common failure and the hardest to detect because Claude confidently executes what it remembers, which may not be what you wrote. Now stay with me on this one, because the deeper problem is precedence rather than truncation. A compressed plan does not just get vaguer; it loses authority against the model’s default habits. A documented Claude Code issue describes the result: Claude starts sampling files with grep and partial reads instead of reading them in full as the plan asked, then edits from incomplete context.
Attention drift. This one looks like compression from the outside, but it is a different beast. Worth separating, because the fix is different. After 30+ tool calls across many turns, Claude’s focus on the original plan weakens even before compression hits. The model optimizes for the immediate task in front of it, not the distant plan that started the session. This is basically scope creep at the AI level. Think about how a step expands once you start it. Step 5 says “update the config file.” You start, and the config file has a related setting that looks wrong, so you fix that too. Then a test breaks, so you trace the test. Each of those side quests is reasonable on its own. But every one of them pushes the original plan further down the context and further out of attention. By the time the side quests resolve, the model is deep in a problem the plan never mentioned, and the next numbered step has quietly stopped feeling like the next thing to do. Nothing went wrong in any single decision. The plan just stopped being the center of gravity.
No accountability mechanism. CLAUDE.md can say “verify every step” a hundred times. Nothing enforces it. Claude reads the instruction, intends to follow it, and then doesn’t because nothing prevents it from saying “done” without checking. Written rules are suggestions. They are not gates. The distinction matters more than it sounds. A suggestion depends on the reader holding it in mind at the moment it applies. The moment a verification rule applies is the very end of a long session, which is exactly the moment that rule is most likely to have been compressed or buried under thirty tool calls. So the instruction is weakest precisely when you need it. A gate has the opposite shape. It does not depend on anyone remembering it. It sits at the exit and checks, and it checks the same way on turn one and turn three hundred. If your only enforcement is text, you have built a rule that gets quieter as the session gets riskier.
Overconfidence. Is Claude deliberately cutting corners? No. This is the one that surprised me, and frankly I have doubts “overconfidence” is even the right label, but it is the closest single word. Claude doesn’t skip steps maliciously or lazily. It believes it completed everything. It declares “done” based on its memory of what it did, not verification of the actual files. If I am being straight, this is the same pattern I see in human developers who skip code review because they are “sure” it is right.
The anti-patterns show up in Claude’s language:
- “I have made the key changes, the rest is minor”
- “The remaining steps are similar so I will summarize”
- “This should be straightforward so I won’t verify”
- “I will skip this for now”
Every one of these is a missed step waiting to happen. Read them again and notice what they share. Each one is a small, reasonable-sounding judgment call. “The rest is minor” might even be correct. “The remaining steps are similar” often is. The danger is not that the judgment is wrong; the danger is that the judgment was made at all. A plan is a contract. The moment Claude starts deciding which parts of the contract still apply, the plan has stopped being a plan and become a set of options. And the part it decides to drop is, by definition, the part you did not get to weigh in on. If a step does not really need doing, that is a decision for you to make out loud, not for the model to make silently on your behalf while you assume the whole list got executed.
The fifth failure mode is different, because it happens before Claude executes anything. After working through this for a while, the cleanest way I can frame it: the plan itself was incomplete. It was built on requirements I never thought to give, so Claude produced a confident, internally consistent plan for the wrong job. This is the “I don’t know what I don’t know” problem, and no hook can catch it. A Stop hook verifies that every step ran. It has no way to verify that the steps were the right ones.
The fix for this mode is not enforcement. Let me say that better: the fix is prevention, not enforcement, and it belongs in plan mode, before execution starts. Anthropic’s own best-practices guide names the technique: instead of handing Claude a spec, have Claude interview you first. Start with a minimal prompt and ask it to question you, so it surfaces, in the guide’s words, “things you might not have considered yet, including technical implementation, UI/UX, edge cases, and tradeoffs.” A five-minute interview that exposes a missing requirement is cheap. Finding that requirement after Claude has executed a confident, wrong plan is not.
So the full defense has two halves. Prevention catches the wrong plan. Enforcement catches the right plan executed badly. The rest of this post is about enforcement, the half I had to build myself, but neither half works alone.

Three layers that actually work

The solution has three layers, each catching what the previous one misses.
Layer 1: CLAUDE.md instructions (soft enforcement). Written rules about plan discipline. Anti-patterns to avoid. A mandatory verification protocol. This works when Claude has attention on it, which in short sessions is most of the time. In long sessions, these instructions fade as context compresses. Think of this as the honor system (and yes, the honor-system metaphor is doing more work here than honor systems usually do, but it captures the essential trust-but-no-enforcement shape). Effective, but not sufficient.
Specific additions to CLAUDE.md that made a difference:
- An explicit list of anti-patterns (“never say ‘I will skip this for now’”)
- A mandatory self-verification protocol (“re-read the plan file, don’t rely on memory”)
- A structured output format for verification (the Plan Completion Check with checkboxes)
- Healthy skepticism rules (“assume you probably missed something, verify”)
Why keep Layer 1 at all if it fades? Because it does most of the work, and it does it cheaply. In a short session the written rules are still in context, still carry weight, and Claude follows them without anything else needing to fire. A hook that triggered on every session would be solving a problem that, most of the time, is already solved. The honor system is not weak. It is just incomplete. You keep it because it handles the common case for free, and you add the next layers to handle the case the honor system structurally cannot reach: the long session where the honor code itself has been compressed away.
Layer 2: Structured verification output (medium enforcement). What I keep seeing in process-design work is that structured outputs hold a model’s behavior better than freeform prose, and this is the same pattern in miniature. The “Plan Completion Check” is a specific markdown section with checkboxes that Claude must produce:
## Plan Completion Check
- [x] Step 1: Create hook script - DONE
- [x] Step 2: Configure settings.json - DONE
- [ ] Step 3: Update CLAUDE.md - NOT DONE: file not foundThis creates accountability through structure. It is harder to skip a checklist than to skip a vague instruction. Claude has to look at each step individually and declare its status. The act of writing “DONE” forces verification, at least in theory.
The “at least in theory” is doing real work in that sentence, so let me be clear about why the layer is only medium strength. A checklist makes skipping a step visible, but it does not make lying impossible. A model running on a compressed plan can produce a clean Plan Completion Check where every box is ticked, because it is checking the boxes against its memory of the plan, not against the files. The structure forces it to make a claim per step. It does not force that claim to be true. So Layer 2 raises the cost of a silent miss and gives you something concrete to read, which is worth a lot. But it shares the same blind spot as Layer 1: if the plan has already faded, a confident model will fill the checklist out confidently and wrongly. That is the exact gap Layer 3 exists to close, and it is why a checklist alone was never going to be enough.
Layer 3: Stop hook (hard enforcement). This is where it gets tricky, and where I had to stop treating enforcement like a politeness problem. A bash script that physically blocks Claude from stopping. It reads session context, checks if a plan file was written or edited in this session, and verifies the Plan Completion Check section exists in Claude’s response. If the check is missing, the script returns exit code 2. Claude can’t stop. It must produce the verification.
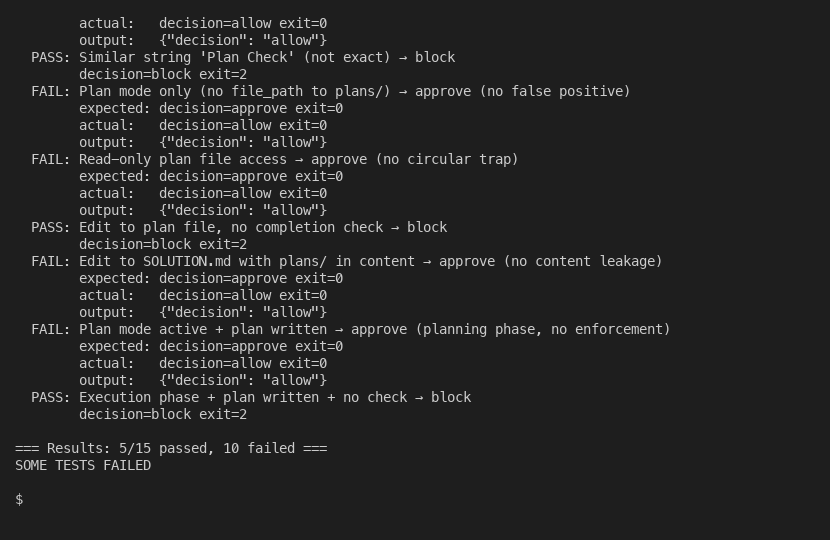
The hook runs on every turn. When Claude has completed the check, it is silent (exit 0). When Claude tries to stop without it, it blocks visibly. The overhead is roughly 1-5 milliseconds per turn for the command hook. Negligible.
The layers are complementary. Layer 1 catches 80% of cases through good instructions. Layer 2 catches another 15% through structured output. Layer 3 catches the remaining 5% where Claude would have stopped without verifying. That last 5% is where the important misses happen.
Hmm, that needs unpacking. It is worth being precise about why a stack of three layers beats one strong layer. The three layers do not just add up; they fail in different ways, and that is the point. Layer 1 and Layer 2 both depend on the model still having the plan in context and still wanting to comply. When a session goes long enough that those assumptions break, both layers break together, for the same reason, at the same time. If they were your only defenses you would have no defense at all in the case that matters. Layer 3 does not share their failure condition. It is a separate process. It does not read a compressed plan; it reads the transcript on disk. It does not need Claude to want to comply; it returns an exit code whether Claude wants it or not. So the right way to picture the stack is not three filters of decreasing size. It is two filters that catch the easy cases cheaply, plus one backstop built specifically to survive the moment the first two stop working. The 5% is small. It is also the slice with your name on it, because it contains the long, high-stakes sessions where you were counting on the plan most.
Layer 4: an independent auditor (when string-match is not a check)
I said above that the three layers catch 80, 15, and 5 percent of cases respectively. That oversimplifies it. Those percentages assume the plan was right to begin with. Once you account for the fifth failure mode (wrong plan, not wrong execution), the three-layer stack is closer to 80-15-5 of the cases it actually addresses, and there is still a slice it cannot reach. Layer 4 lives in that slice.
The three layers above are enough for almost everyone. If your sessions are short, your plans are small, and your work is mostly text edits, stop reading here.
If your plans run to a dozen steps and your sessions burn forty turns, there is a fourth layer worth knowing about. Layer 3 catches the case where Claude tries to stop without writing the Plan Completion Check. It does not catch the case where Claude writes the check, ticks every box, and lies. The structure is satisfied. The grep matches. The hook approves. Half the boxes were ticked from memory, against a compressed plan, and the files those boxes claim to have changed never moved a byte. Layer 3 cannot tell the difference.
Layer 4 can, because Layer 4 is a second model. I swing both ways on whether to recommend it for everyone or only for plan-heavy sessions, and the real answer is the latter. The Stop hook spawns a fresh claude -p sub-agent, gives it the plan file and the actually-modified file contents inline, and asks it to report drift across four categories: claimed-but-not-on-disk, done-but-plan-stale, abandoned-but-still-in-plan, and todos-without-plan-step. The sub-agent has no memory of the parent session, so it cannot parrot what the parent claimed. It can only read what is there. The verdict goes into the Stop hook’s reason field, which reaches the parent on its next turn. The parent then has to address each item by name, or update the plan to reflect reality.
There is a name for what that sub-agent does. It is Chain-of-Verification, a method Meta researchers published for cutting hallucination: take a claim, turn it into a list of check questions, answer each one on its own, then let the answers correct the claim. The drift categories are those check questions. The fresh context is what stops the same mind from answering for its own work. I did not invent the idea. I wired it into the one moment a coding session is most likely to lie, which is the moment it wants to stop.
For a while that verdict only mattered when the completion check was missing. If Claude wrote the check, the hook approved and ignored whatever the auditor had found. Once I logged the decisions I could see the hole: about a third of the approved sessions carried a real finding the hook had waved through, because the string was present and that was all it checked. So the gate moved off the string. The hook now reads the verdict and blocks on a confirmed finding even when the completion check is sitting right there.
That raises an obvious risk. The auditor is a small, low-context model, and it is wrong often. It cannot see a file edited on a remote machine, or content that was truncated before it reached the prompt. So it never gets the last word. A confirmed finding blocks the stop once, the loop guard lets the next stop through regardless, and on that one turn the full-context parent either fixes the miss or explains why the finding is a false positive. The auditor flags only what it can stand behind as confirmed. Everything it is unsure of is marked cannot-verify and surfaced without blocking. The witness raises the concern. The session, which can see what the witness cannot, makes the call.
The last gap was scope. A hook that only fires when a plan file was touched misses every session that did real work without one, and the same false “done” (a file claimed but never written, an issue claimed but never filed) happens just as often there. So the auditor now also runs on substantive non-plan sessions, with no completion check required, blocking only when it can confirm a fabrication.
The cost is real: about half a cent per session and ten to thirty seconds of latency at end-of-turn. Worth it for substantive plan-mode work; overkill for one-line edits. The implementation, plus three bugs the build surfaced (including one that silently broke every block for two days), is written up in the Stop hooks deep-dive. For most readers, Layers 1 to 3 are enough. Layer 4 is for the day they are not.
Setting it up yourself
The full system requires three pieces: a script file, a settings.json entry, and CLAUDE.md updates.
Step 1: Create the hook script at ~/.claude/hooks/plan-verify.sh:
#!/bin/bash
set -euo pipefail
# Require jq
if ! command -v jq &>/dev/null; then
echo '{"decision": "block", "reason": "jq required. Run: brew install jq"}'
exit 2
fi
CONTEXT=$(cat)
LAST_MSG=$(echo "$CONTEXT" | jq -r '.last_assistant_message // empty') || LAST_MSG=""
TRANSCRIPT=$(echo "$CONTEXT" | jq -r '.transcript_path // empty') || TRANSCRIPT=""
PERM_MODE=$(echo "$CONTEXT" | jq -r '.permission_mode // empty') || PERM_MODE=""
# Skip enforcement during planning phase
if [ "$PERM_MODE" = "plan" ]; then
echo '{"decision": "allow"}'
exit 0
fi
# Check if this session wrote/edited a plan file
HAS_PLAN=0
if [ -n "$TRANSCRIPT" ] && [ -f "$TRANSCRIPT" ]; then
HAS_PLAN=$(grep '"file_path" *: *"[^"]*\.claude/plans/' "$TRANSCRIPT" \
| grep -c '"Write"\|"Edit"') || HAS_PLAN=0
fi
if [ "$HAS_PLAN" -eq 0 ]; then
echo '{"decision": "allow"}'
exit 0
fi
if echo "$LAST_MSG" | grep -q 'Plan Completion Check'; then
echo '{"decision": "allow"}'
exit 0
fi
echo '{"decision": "block", "reason": "Plan Completion Check required."}'
exit 2Make it executable: chmod +x ~/.claude/hooks/plan-verify.sh
The grep pattern '"file_path" *: *"[^"]*\.claude/plans/' deserves explanation. The [^"]* part is critical. It means “match any characters that are not a double quote.” This anchors the match inside the file_path JSON value string, preventing false positives when .claude/plans/ appears in edit content of other files. Without this anchor, editing a documentation file that mentions plans would trigger the hook. That was bug number 4 of 6.
Step 2: Configure settings.json. Add to ~/.claude/settings.json:
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "~/.claude/hooks/plan-verify.sh",
"timeout": 10
}
]
}
]
}
}Use an external script file, not inline bash. Claude Code has a documented escaping bug that corrupts | in jq expressions, marked “not planned” so it won’t be fixed, and a pipe buried inside an inline command is exactly where that class of corruption hides.
Step 3: Update CLAUDE.md with the Plan Completion Check format, the anti-patterns list, and healthy skepticism rules. The key addition is telling Claude that a Stop hook will block it if the check is missing. Claude reads CLAUDE.md at session start and knows the hook exists, which reinforces compliance even before the hook fires.
Step 4: Build a test suite. Do not trust any hook without regression tests. I found bugs 2 through 6 through synthetic testing, not through production failures. The test suite runs 15 scenarios covering false positives, circular traps, content leakage, planning phase bypass, and edge cases. Look, testing a 60-line bash script with 15 tests might seem like yak shaving, and I went back and forth on whether that level of testing was proper engineering or just nervousness about a small script. It isn’t yak shaving. Every bug was caught by testing, not by code review.
Since then the suite has outgrown that script. It is up to 62 tests across five files now, with the auditor sub-agent mocked so the runs are deterministic, and an A/B mode that puts the old and new decision logic through the same fixtures side by side. That round of work turned up two more bugs the first fifteen tests would never have reached: a message filter that quietly dropped real user text, and a fallback that demanded a completion check from a session that never had a plan.
Here is the part that makes the test suite non-negotiable rather than nice to have. This is not ordinary code. A hook is enforcement code, and enforcement code fails in a way that hides itself. If a normal script has a bug, something breaks and you notice. If this script has a bug, the most likely outcome is that it stops blocking. It returns exit 0 when it should have returned exit 2, the session ends cleanly, and you see exactly what you saw before you ever wrote the hook: a confident “done.” There is no crash, no red text, no signal that your safety net has a hole in it. You would only find out the next time a step got skipped, which is the failure you built the hook to prevent in the first place. So you cannot wait for production to surface these bugs, because a broken hook produces a silent production that looks identical to a working one. The 15 tests are not there to prove the script runs. They are there to prove it still says no when it is supposed to say no. That is the only property that matters, and it is the one property you can never confirm just by watching a successful session go by.
What changed and what is still broken
After deploying the system, I ran two live end-to-end tests.
Test 1: Happy path. Created a simple plan, executed it, included the Plan Completion Check. The hook ran silently on every turn, approved everything, and the session completed normally. This proved the hook doesn’t interfere with normal work.
Test 2: Enforcement path. Created a plan and deliberately told Claude to skip the Plan Completion Check. Claude executed the plan, said “Done,” and tried to stop. The hook blocked it. Claude acknowledged the block, re-read the plan file, verified each step, produced the Plan Completion Check with checkboxes, and the hook approved the second attempt.
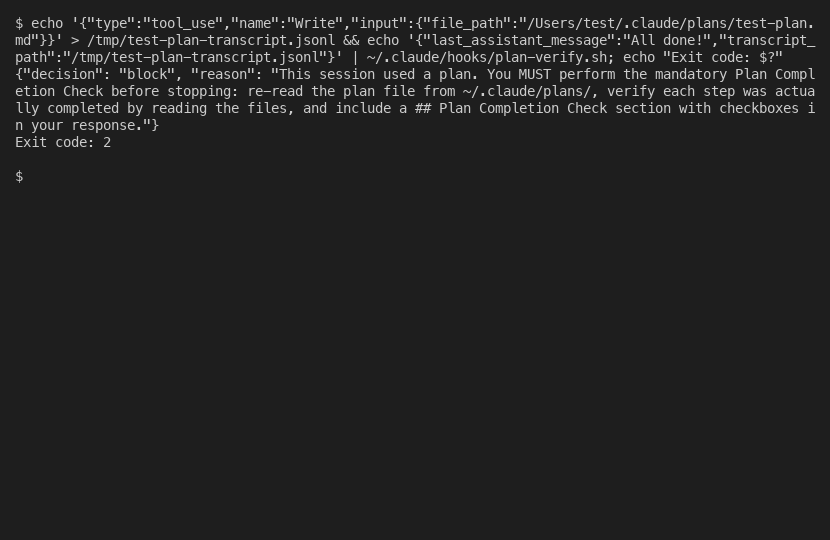
That second test is the proof. The hook caught an incomplete plan execution and forced Claude to finish it. Before this system, that would have been a silently skipped verification.
Notice what the enforcement path actually proves, because it is more than “the hook can say no.” It proves the loop closes. The hook blocks, Claude reads the block, Claude goes back to the plan file, works through the steps, produces the check, and the second attempt passes. That recovery is the whole design. A gate that only stopped Claude without giving it a way to continue would be a dead end; you would trade silent misses for stuck sessions. What you want is a gate that converts “I am done” into “I am not done yet, here is what is left, now I am done.” The block is not the goal. The block is the prompt that sends Claude back to do the verification it skipped. The two tests together show both halves: the happy path proves the gate stays out of the way when work is complete, and the enforcement path proves the gate produces finished work, not just a halt.
Wait, before I go further on results, I should say a word about how the system tells you it’s working, because it largely doesn’t. Approved hooks are silent. No “Ran 1 stop hook” message. Only blocks produce visible output. This means you can’t visually confirm the hook ran on success. You know it works because blocks are caught, not because approvals are visible. This is uncomfortable at first, and it is worth getting used to rather than fighting. The instinct is to want a green checkmark every turn, some proof the net is still under you. You do not get one. But think about what the silence is telling you. A silent hook on a complete session and a silent hook on a session where the hook never loaded look exactly the same from the outside. That is the real argument for the test suite from the previous section: tests are how you earn the right to trust the silence, because tests are the only place the hook ever has to prove out loud that it still blocks.
What is still broken (real assessment):
The Stop hook doesn’t fire on “silent tool stops” (issue 29881). When Claude receives a tool result but stops without generating text, the hook never fires. The session stalls. Only manual intervention fixes it.
False “hook error” labels appear in the transcript for every hook execution, even successful ones (issue 34713). With many tool calls, these false errors inject hundreds of entries into context, which can cause Claude to prematurely stop thinking something is broken.
Hooks occasionally don’t load from settings (issue 11544): version 2.0.37 stopped loading them from a valid settings.json. Hook regressions happen across versions.
And CLAUDE.md instructions still fade in long sessions. The hook is a safety net, not a replacement for good instructions. Both matter. That said, the hook catches the cases that matter most: when Claude would have declared “done” without verifying, and when context compression has already erased the written rules.
Be clear-eyed about what that list of broken things means for you. The hook has a known gap on silent tool stops, it generates noisy error labels, and it can fail to load across versions. None of those are reasons to skip building it. They are reasons to keep watching it. A safety net you installed and then forgot about is worse than no net, because you start trusting it without checking it. The right posture is the same one the hook enforces on Claude: assume you probably missed something, and verify. When a version update lands, re-run the test suite before you trust a single session. When a session stalls instead of finishing, do not assume the hook fired and the work is done. Manual intervention is still part of the system. The hook removes the most common and most invisible failure, the silently skipped step. It does not remove your judgment, and on the long, important jobs your judgment is still the last line.
Plans are not the hard part. Follow-through is. The more I look at it across long sessions, the more obvious that becomes. This system doesn’t make Claude perfect at follow-through. It makes Claude incapable of skipping it.





